Tento poloprovoz vznikl na základě institucionální podpory dlouhodobého koncepčního rozvoje výzkumné organizace Národní knihovna České republiky, která je poskytována Ministerstvem kultury.
Cíle
Z hlediska koncových uživatelů z řad zainteresované veřejnosti je hlavním cílem zprostředkování obsahu edic historických textů podstatně přístupnější formou než je tradiční tištěná podoba. Zároveň je nutno maximálně využít možnosti digitálního prostředí, mimo jiné ve vztahu k paralelnímu zobrazování zrekonstruovaného textu edice s jeho originálními zápisy či vydáními v historických dokumentech.
Podobně jako vlastní digitalizované dokumenty je zapotřebí edice textů v nich obsažených systematicky agregovat a nabídnout uživatelům možnost strukturovaného hledání, třízení a ukládání plnotextových dat. Součástí prezentovaného komplexního nástroje je tak i katalog plnotextových edic. Tím vzniklo alternativní vyhledávací jádro, které uživatelům Manuscriptoria umožňuje práci s digitalizovaným obsahem nikoliv podle logiky obrazů, nýbrž s primárním zřetelem k jejich textovému obsahu.
Technické řešení
Tato kapitola shrnuje výsledky nového vývoje, jakož i významná rozšíření stávající softwarové infrastruktury. Zaměřuje se na technická řešení, která podporují práci s plnotextovými edicemi historických dokumentů, jejich dlouhodobou správu, automatizované zpracování a moderní způsoby zpřístupnění koncovým uživatelům.
Datový model
Základem celé infrastruktury je nově rozšířený datový model, který je realizován jako graf uložený v grafové databázi. Tento model lze chápat jako ontologii plných textů, která formálně popisuje jednotlivé entity (plné texty, jejich strukturální části, edice, překlady, fyzické exempláře, stránky, autory aj.) a především jejich vzájemné vztahy. Grafový přístup byl zvolen z důvodu své flexibility a schopnosti přirozeně zachytit složité a mnohovrstevnaté vazby, které jsou pro historické texty typické.
Datový model byl v rámci projektu významně rozšířen o podporu variantních struktur. Díky tomu je možné systematicky zpracovávat variantní edice téhož díla a modelovat jejich vztahy k původnímu, byť abstrahovanému textu a jednotlivým pramenům, které jej přechovávají. Model tak umožňuje postihnout nejen lineární podobu textu, ale i jeho historický vývoj, redakční zásahy a rozdílné ediční přístupy.
Důležitým rozšířením datového modelu je možnost zachycení překladů a jejich vazeb k originálním textům. V současném fondu plných textů se vyskytují překlady v několika úrovních granularity. U některých děl jsou překlady realizovány na úrovni vyšších strukturních celků, jako jsou např. kapitoly (odpovídající elementům <div> dle standardu TEI P5), v jiných případech jsou překlady vztaženy přímo k nižším strukturním jednotkám typu odstavce nebo verše, které zde označujeme souhrnným termínem „strukturní fragment“. Datový model umožňuje v obou případech explicitně vyjádřit, který strukturní celek překladu odpovídá konkrétnímu strukturnímu celku v originálním textu. Tím je vytvořen pevný základ pro paralelní práci s originálem a překladem i pro jejich společné zpřístupnění v uživatelském rozhraní.
Datový model byl dále rozšířen s ohledem na skutečnost, že u historických textů – zejména v případě středověké literatury – se podoba textu edice často výrazně liší od způsobu, jakým je text zachycen v konkrétních zápisech či jednotlivých historických vydáních.
Plynulý text edice, který je výsledkem odborné redakční práce, nebývá v rukopisech nutně uveden souvisle ani v jednotném pořadí a může být uváděn na různých místech korelovaného rukopisu. Model proto umožňuje oddělit logickou strukturu edičního textu od jeho fyzické realizace v exempláři. Ediční text je v datovém modelu chápán jako abstraktní, plynulá sekvence textových jednotek (strukturních celků různé úrovně), zatímco rukopisný exemplář je reprezentován jako specifická materializace tohoto textu, v níž mohou být jednotlivé bloky textu umístěny na různých místech a v odlišném pořadí.
Každý strukturní fragment edičního textu tak může být propojen s jedním či více místy (folio, strana) v jednom nebo dokonce ve více konkrétních exemplářích, přičemž tyto vazby nejsou omezeny na lineární vztah „za sebou“, ale umožňují plně obecné grafové propojení. Takto koncipovaný datový model vytváří pevný základ pro pokročilé způsoby práce s historickými texty, zejména pro korelované čtení edičního textu a rukopisného exempláře, v korelaci s jednotlivými dochovanými prameny.
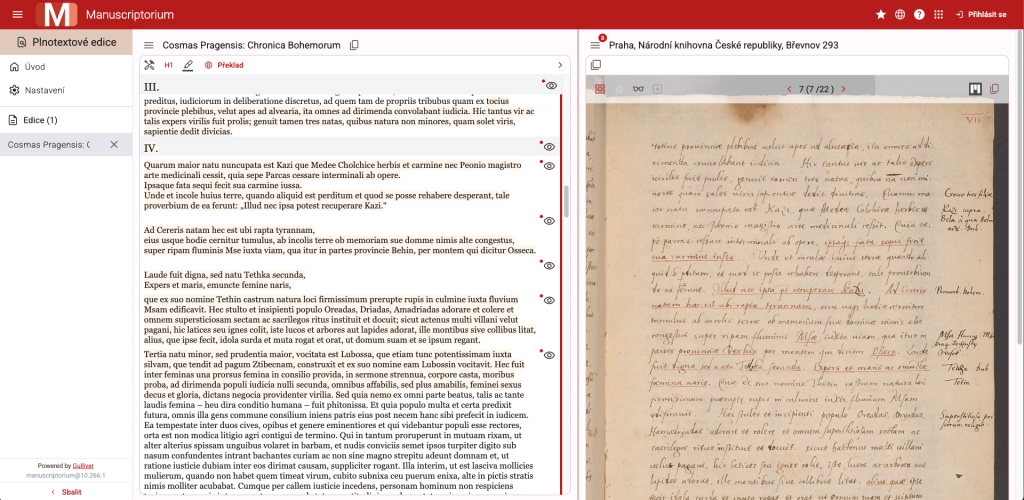
Automatizace agregace plných textů
Pro agregaci plných textů je v projektu využívána platforma Invenio DL, která slouží jako centrální bod pro jejich shromáždění, správu a publikování. V rámci realizovaných úprav byl kladen důraz na maximální míru automatizace procesů spojených s vkládáním a aktualizací plných textů.
Agregované plné texty jsou v systému identifikovány na základě rozšířeného souboru popisných informací, mezi které patří zejména údaje o autorovi, titulu, editorovi a dalších relevantních charakteristikách edice. Tento přístup umožňuje automatizované rozpoznání nových nebo aktualizovaných plných textů a podporuje i průběžnou hromadnou aktualizaci již existujících plných textů bez nutnosti manuálních zásahů.
Součástí agregačního procesu je rovněž přiřazení jednoznačného identifikátoru každému plnému textu. Tento identifikátor je následně využíván napříč celou infrastrukturou, a to jak při interním zpracování, tak při publikování a výměně dat s externími systémy.
Pro disseminaci a zpřístupnění agregovaných plných textů je využíván protokol OAI-PMH. V rámci projektu byl definován dedikovaný OAI-PMH set spolu s odpovídajícím metadata formátem, který umožňuje cílené poskytování plných textů a souvisejících informací dalším systémům a službám. Tento způsob publikování zajišťuje interoperabilitu řešení a jeho zapojitelnost do širšího ekosystému digitálních knihoven a badatelských infrastruktur.
Nová zpracovatelská linka pro plnotextové edice
Jedním z klíčových výsledků vývoje je implementace nové výrobní linky, která zajišťuje automatizované zpracování plných textů od jejich získání až po zpřístupnění pro čtení a vyhledávání. Výrobní linka je postavena na OAI-PMH harvesteru a je přímo napojena na platformu Invenio DL, odkud získává aktuální data.
Výrobní linka plní několik základních funkcí. V první fázi provádí sklizeň (harvesting) plných textů z Invenio DL. Následně aktualizuje ontologii plných textů v grafové databázi, která slouží jako datový základ pro čtení plných textů a navigaci v jejich struktuře. Tím je zajištěno, že změny v agregovaných datech se promítají do čtecích a prezentačních nástrojů konzistentním způsobem.
Další důležitou součástí výrobní linky je indexace obsahu plných textů do vyhledávací infrastruktury založené na Castor/SOLR. Indexovány jsou jednotlivé strukturní fragmenty plných textů, což umožňuje jemnozrnné vyhledávání na úrovni odstavců, veršů či dalších strukturálních jednotek. Tato indexace tvoří základ pro pokročilé vyhledávání v plných textech v uživatelském rozhraní.
Výrobní linka je rovněž integrována se systémem IdH, který je využíván k získávání identifikátorů fyzických exemplářů. Díky této integraci je možné korelovat plné texty s konkrétními stránkami digitalizátů fyzických exemplářů. Tato vazba je klíčová pro následné propojení textu a obrazu a pro podporu korelovaného čtení historických dokumentů.
Automatické obohacování o informace z externích zdrojů
Formát TEI P5 umožňuje v rámci textového markupu uvádět nejen vlastní textové hodnoty, ale také odkazy na externí informační zdroje, jako jsou autoritní databáze, řízené seznamy či otevřené znalostní báze. Tyto reference jsou v projektu systematicky využívány jako součást datového modelu plných textů a tvoří jeden z mechanismů, jimiž je text propojen s širším informačním kontextem.
Autoři plných textů mohou při označování entit (např. osob, míst, klíčových pojmů) uvádět základní textovou podobu a současně referenci na externí zdroj. Autor tak není nucen zaznamenávat všechny varianty jména či názvu přímo v textu, ale pracuje s jednoznačnou identifikací entity.
Na základě těchto referencí systém v reálném čase automaticky načítá doplňující informace z externích zdrojů, zejména jazykové varianty jmen, alternativní názvy a překlady. Tyto informace jsou dále využívány v prezentační vrstvě.
Automatické obohacování tak přispívá ke snížení redundance informací napříč fondem plných textů a podporuje konzistenci dat v celém systému. Zároveň vytváří předpoklady pro pokročilé způsoby práce s texty, například pro jednotné vyhledávání osob či míst napříč edicemi, nebo pro jejich kontextualizaci v uživatelském rozhraní.
V rámci projektu bylo toto řešení realizováno s využitím integrace na otevřenou znalostní bázi Wikidata. Použité principy jsou však obecné a umožňují další rozšiřování o jiné externí informační zdroje, zejména autoritní databáze, pokud poskytují odpovídající aplikační rozhraní.
Nová generace end-user rozhraní
Na úrovni koncového uživatele byl realizovaný vývoj promítnut do nové generace uživatelského rozhraní, které reflektuje možnosti nové datové a aplikační infrastruktury. Rozhraní je navrženo tak, aby podporovalo pokročilou práci s plnotextovými edicemi, jejich širší kontextualizaci a srovnávání.
Jednou z funkcionalit je korelované čtení plnotextových edic ve spojení s externími digitalizáty. Rozhraní bylo rozšířeno o podporu cizích digitalizátů prostřednictvím standardů IIIF Presentation API a IIIF Image API. Díky tomu je možné současně zobrazovat vlastní plný text spolu s digitalizovanými stránkami rukopisu či tisku uloženého v IIIF repositáři externí instituce, aniž by bylo nutné mít digitální kopii exempláře agregovanou v Manuscriptoriu. Toto řešení významně rozšiřuje možnosti práce s prameny a podporuje mezinárodní spolupráci.
Součástí nové generace rozhraní je také Katalog plnotextových edic, který umožňuje jednotné vyhledávání jak v metadatech plnotextových edic, tak v jejich vlastním textovém obsahu. Technicky je toto řešení založeno na kombinaci komunikace se dvěma samostatnými Castor/SOLR jádry. První jádro obsahuje metadata edic, kde je základní jednotkou záznam odpovídající edici, resp. plnému textu jako celku. Druhé jádro je zaměřeno na samotný obsah edice a pracuje se strukturními fragmenty textu, jako jsou odstavce či verše. Mezi aplikační vrstvou katalogu a vyhledávacími jádry je vloženo interceptor API, které přebírá dotazy, podle jejich kontextu je směruje do jednoho, druhého nebo obou jader a následně normalizuje odpovědi do jednoho výsledku. Uživatel tak získává jednotné rozhraní bez nutnosti vnímat technickou složitost řešení.
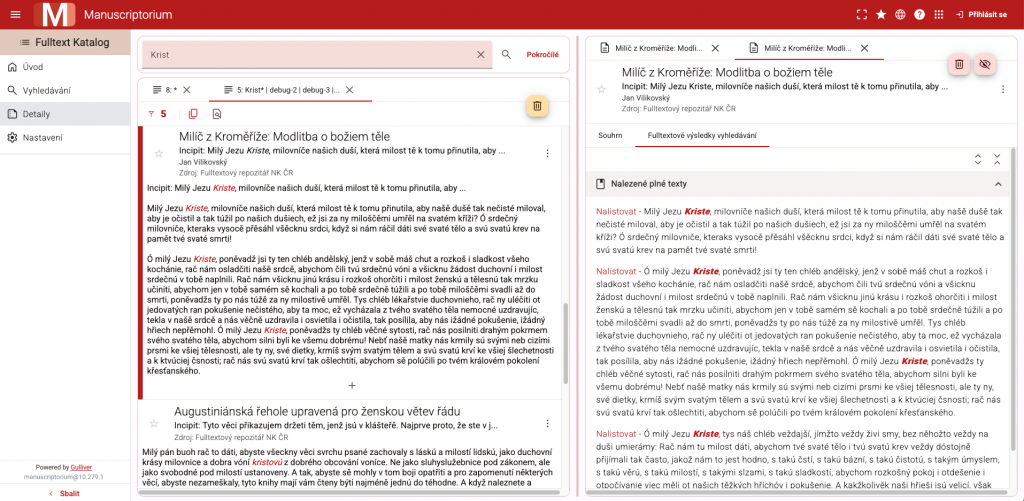
Významnou pozornost jsme věnovali také podpoře pokročilého poznámkového aparátu. Funkcionalita byla výrazně přepracována a rozšířena s cílem lépe pokrýt potřeby kritických edic. Jako referenční případ byla využita edice Kosmovy kroniky editora Bertolda Bretze, na jejímž základě byly navrženy a ověřeny nové možnosti práce s poznámkami, jejich strukturou a vazbami k textu.
Dalším novým prvkem je zavedení specializovaného rozhraní pro práci s překlady. Uživatelé mohou přehledně pracovat s překlady na úrovni oddílů i jednotlivých strukturních fragmentů textu a sledovat jejich vztah k originálu. Toto rozhraní přímo využívá rozšířeného datového modelu a umožňuje paralelní čtení originálního textu a jeho překladu.

Jednou z nezbytných podmínek pro tvorbu robustní fulltextové databáze a její funkční integrace do systému Manuscriptoria je také persistentní identifikace jednotlivých edic. Jako unikátní musí být procesován nejen konkrétní historický text, ale i různé edice téhož textu či překlady do moderních jazyků. Proto jsou edice propojeny s Resolverem Manuscriptoria.
Odkazy
- Katalog plnotextových edic
- Čtečka plnotextových edic
- Ukázka persistentního odkazu přes resolver:
https://www.manuscriptorium.com/apis/resolver-api/cs/fulltext/default/edition/r-21082/cosmas-pragensis/chronica-bohemorum/edt-bertold-bretholz - Odkaz na OAI-PMH set plných textů:
https://ssorst.nkp.cz/oai2d?verb=ListRecords&metadataPrefix=teiftt&set=rastis:ftt