Tento poloprovoz vznikl na základě institucionální podpory dlouhodobého koncepčního rozvoje výzkumné organizace Národní knihovna České republiky, která je poskytována Ministerstvem kultury.
Cíl
Cílem prací bylo generování popisných metadat pro digitalizáty agregované v Manuscriptoriu pomocí umělé inteligence (AI). Klíčová slova, indikátory a popisné informace vytvořené pomocí AI obohacují obsah agregovaný v Manuscriptoriu, což vede ke zlepšení třídění a vyhledávání těchto historických dokumentů. Zároveň umožnují implementaci nových funkcí v koncovém uživatelském rozhraní, které zkvalitňují user-experience. Součástí realizace byl návrh a zavedení nových procesů do zpracování dat i vývoj nových a úpravy existujících softwarových nástrojů, z nichž některé jsou zveřejněny jako open source pro použití v dalších paměťových institucích.
Pozadí vzniku záměru
Na základě zkušeností s agregovanými daty a popisnými metadaty bylo ověřeno, že jsou partnery poskytována v různé kvalitě, ať již jde o informační rozsah, strukturu nebo využívání referencí na položky formálních slovníků. Manuscriptorium si nikdy nekladlo za cíl posuzovat kvalitu partnery poskytovaných dat a metadat (s výjimkou všeobecné osvěty nebo explicitně vyžádané podpory pro dosažené good practice při plnění role Manuscriptoria jako doménového agregátora projektu Europeana). Nicméně v rámci projektu ARMA jsme ve spolupráci s vybranými evropskými paměťovými institucemi definovali good practice pro optimální rozsah záznamu středověkých rukopisů ve formátu EDM (Euroepana Data Model).
Přirozeně se potvrdilo, že pro systematickou práci při obohacování agregovaného obsahu „good practice“ informacemi v měřítku Manuscriptoria (statisíce popisných záznamů) chybí a vždy budou chybět lidské zdroje i finance.
Právě proto bylo naším cílem prozkoumat potenciál využití generických modelů dostupných AI a prověřit, zda jsme schopni získat dostatečně kvalitní metadata s minimálními zdroji (čas, finance), a to bez nutnosti trénování vlastních speciálních modelů, zaměřených na středověké rukopisy (kvůli minimalizaci nákladů budoucího provozu a údržby).
Dílčí cíle
- Efektivní plynulé pořizování přesných a relevantních klíčových slov a souvislých anotací pro středověké rukopisy na základě vstupních strukturovaných popisů a obrazových dat.
- Zlepšení třídění a vyhledávání v katalogu Manuscriptoria.
- Nové pokročilé funkce implementované do uživatelského interface díky využití nově získaných metadat a popisů.
- Zvýšení efektivity práce s databází pro odborníky i veřejnost.
Způsob řešení
Workflow zpracování, integrace s AI
Do workflow zpracování dat v Manuscriptoriu jsme implementovali nástroje a procesy, které umožní hromadně zpracovávat agregovaná vstupní data.
Následující diagramy ilustrují způsob řešení:
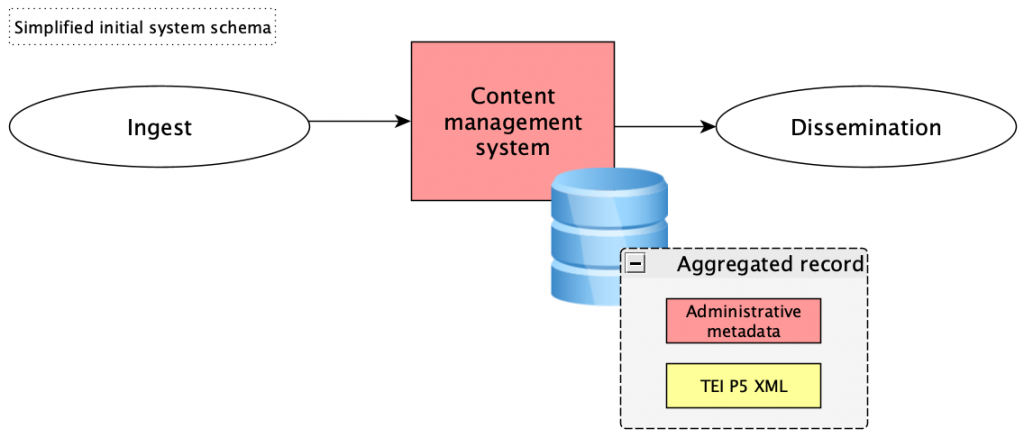
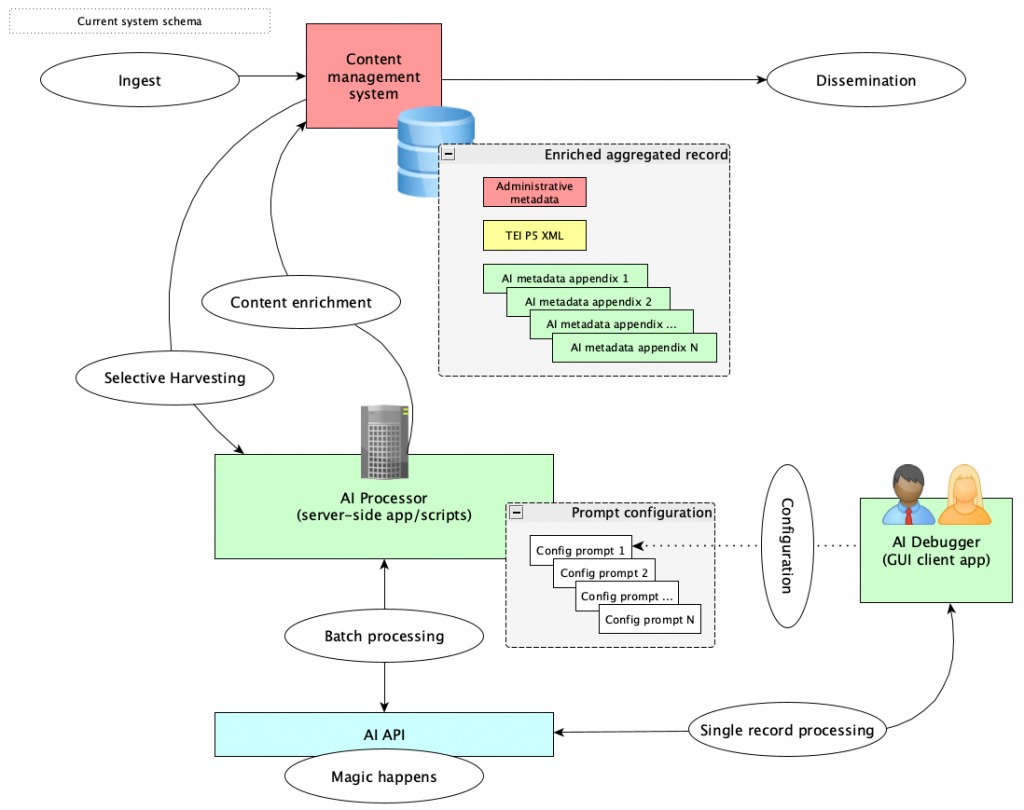
Součástí workflow je nyní integrační bod komunikující s vybranou AI pomocí jejího vlastního aplikačního rozhraní (API). S AI komunikujeme pomocí klíčové komponenty celého řešení, kterým je back-endová aplikace AI Processor.
Komunikace s AI neprobíhá v reálném čase – místo toho AI Processor odesílá dávky ke zpracování a čeká na odpovědi, komunikace je asynchronní. Procesor odesílá v dávkách jednotlivé prompty, zpracovává odpovědí AI a výsledky předává k uložení do správního systému ve formě tzv. přívěsků.
Přívěsky jsou v systému ukládány samostatně a se záznamem příslušného dokumentu jsou propojeny vazbou. Tak je zajištěno, že agregace oficiálního obsahu od partnerů může probíhat nezávisle na existenci přívěsků, a naopak přívěsky mohou být doplňovány či aktualizovány nezávisle na běžné agregační činnosti Manuscriptoria. Systém sběru informací tak může být velmi flexibilně řízen dle aktuálních potřeb provozovatele.
Konfigurace úloh pro AI Processor
AI Processor může současně zpracovávat různě zaměřené úlohy prováděné nad různými podmnožinami obsahu Manuscriptoria. Každá úloha je popsána v konfiguraci úloh. Úloha je definována především těmito vlastnostmi:
- Typ úlohy: jedinečný strojový název dodaný původcem úlohy.
- Kategorie úlohy: aktuálně podporované hodnoty jsou record a canvases – hodnota udává, zda se budou zpracovávat popisné záznamy (TEI P5 XML) nebo obrazová data (má vliv na proces zpracování).
- Selekční kritéria definující cílovou množinu záznamů: využíváme výběr z hlavního katalogu Manuscriptoria.
- Konfigurační balíček: prompt a další nastavení specifická pro úspěšnou komunikaci o úloze.
Pro správné zařazení výsledků úlohy do dalšího zpracování používá procesor při komunikaci se správním systémem navíc ještě informace, které umožní řízení budoucích zpracování (aktualizaci přívěsků):
- Časové razítko počátku zpracování dávky,
- Informaci o producentovi a jeho verzi (o sobě, o AI),
- Identifikátor záznamu, ke kterému se nová metadata vztahují.
Celé workflow je navrženo tak, aby bylo obecně aplikovatelné a získávání informací od AI bylo možné realizovat i nad jinými modely či službami jiných dodavatelů AI. V případě potřeby stačí vyměnit či upravit jediný integrační bod, kterým je místo komunikující s API daného dodavatele. Očekáváme, že systém budeme v budoucnu doplňovat o možnost současně komunikovat s různými AI/modely, například v závislosti na kategorii či typu úlohy.
Kategorie úloh
Record
Představuje procesně jednodušší, jednoprůchodové zpracování, kdy v rámci promptu jsou na vstup zpracování přes API AI dodávány postupně jednotlivé originální záznamy. Tyto záznamy mohou v rámci preprocessingu procházet volitelnou transformací, pokud je taková transformace vhodná a zvyšuje kvalitu odpovědí nebo zlevňuje komunikaci s AI. To je využíváno v těch případech, kdy se za službu platí podle objemu komunikace (transformací může být zjednodušení struktury vstupu, odstranění balastních informací apod.).
Canvases
Zpracování obrazů je složitější, dvoufázové zpracování obsahu zavedené opět pro ty případy, kde se za službu účtuje podle objemu komunikace.
V prvním průchodu je nejprve zpracován celý digitální dokument tak, že všechny obrazy jsou AI odeslány v nízkém rozlišení. Prompt slouží jako síto pro selekci obrazů, které má smysl zpracovávat v druhém průchodu ve vysokém rozlišení
Příklad: první průchod zpracuje úlohu typu „je v obraze stránky ilustrace?“ a druhý průchod vyrobí metadata podle promptu „obsahuje figurální malbu? obsahuje zvířecí motiv? obsahuje heraldický motiv…“ jen u obrazů stránek, kde byla při prvním průchodu detekována ilustrace.
Při realizaci úloh z kategorie canvases úspěšně využíváme protokol IIIF. Součástí realizace je načtení IIIF manifestu, zpracování jeho obsahu po jednotlivých canvasech i odvozování nižších rozlišení pro první fázi pomocí IIIF Image API.
Postup při zavádění úloh do systému
Následující postup je aplikován pro každou úlohu zaváděnou do provozu.
Příprava promptů
Příprava promptů
Příprava kvalitních promptů je alfou a omegou komunikace s AI. Námi aplikovaný způsob implementace neumožňuje vyhodnocování komunikace člověkem-odborníkem a průběžnou korekci v reálném čase (kvůli velkému objemu dávek i s ohledem na asynchronicitu komunikace). Přípravě promptů je tedy potřeba věnovat značné úsilí a prompt je potřeba správně vyladit.
Ladění promptů realizují obsahoví odborníci s využitím aplikace AI Debugger.
Výsledkem jejich práce je tzv. konfigurační balíček.
Konfigurace úlohy v AI Procesoru
Obsahoví odborníci dodají konfigurační balíček administrátorovi Manuscriptoria. Společně si ujasní účel použití. Záměry odborníků projdou finální technickou oponenturou a konfigurační balíček je případně doladěn do optimální podoby.
Společně jsou definována selekční kritéria pro obsah zpracovávaný danou úlohou.
Všechny vstupy jsou spojeny ve finální konfiguraci úlohy.
V této fázi vzniknou také konkrétní požadavky na způsob využití metadat, která budou v dané úloze vznikat.
Úprava diseminačních procesů, kustomizace koncového interface
Administrátoři upraví konfiguraci systému (například doplní filtrovací či vyhledávací položku), programátoři upraví disseminační transformace (pravidla plnění položky) případně upraví interface koncového rozhraní – vše podle záměru původce úlohy, který byl formulován během předchozího kroku.
V této fázi také proběhne výroba vzorových metadat a testování výstupů.
Zavedení do systému
Otestovaná konfigurace je zavedena v režimu automatizace a zpracování dokumentů pak probíhá na pozadí chodu systému při provozu Manuscriptoria.
Konfigurační balíčky
Konfigurační balíček jednotlivé úlohy se skládá z těchto součástí:
- Prompt
- Schéma pro odpověď
- Kategorie úlohy
- Parametry specifické pro konkrétní AI, které ovlivňují kvalitu a variabilitu odpovědí
- (Systémová zpráva pro AI)
Aby byly odpovědi uchopitelné pro další zpracování a struktura generování nových informací pro daný typ úlohy byla konzistentní v čase, zavedli jsme jako součást komunikace závazný předpis pro strukturu odpovědí – Schéma. Prompt odkazuje na Schéma a Schéma odpovídá požadavkům promptu. V případě OpenAI používáme JSON Schema.
Systémovou zprávu vysvětlující roli AI v komunikaci měnit nelze a je stejná pro všechny úlohy, používá se jak v Debuggeru, tak v Processoru.
Pro výrobu a ladění konfiguračního balíčku odborníkem slouží AI Debugger.
Shrnutí zkušeností s testováním různých typů úloh na OpenAI Chat GPT-4o
Během vývoje jsme systém ladili na použití promptů zaměřených na vznik těchto informací:
- Nové popisné informace v různých jazycích
- Překlady existujících popisů
- Klíčová slova a termíny v různých kategoriích
- Booleanovské indikátory popisující obsah
Obecně se velmi osvědčilo generování informací z obsahu digitálních obrazů a jeho efektivita při provedení dvoufázovou cestou. Použití booleanovských indikátorů se v první i v druhé fázi zpracování ukázalo jako vysoce spolehlivé. V první fázi zpracování se vyskytly falešně pozitivní výsledky u poškozených dokumentů (poškození typu větší inkoustové skvrny), naopak k falešně negativním výsledkům nedocházelo vůbec, což potvrzuje vysokou funkčnost tohoto kroku. Ve druhé fázi se úpravami promptu dařilo opět dosáhnout vysoce přesných výsledků. S vhodným promptem, schématem a nastavením parametrů pro AI jsme byli schopni dosáhnout prakticky deterministických odpovědí.
Jednodušší, resp. na určitý typ úkolu specificky zaměřené prompty vykazovaly vynikající přesnost a spolehlivost, zejména v případě generování rozvitého textu. Při generování nových popisných informací na základě obsahu (souhrn) byly počáteční výsledky příliš obecné, následné zpřesnění promptu pak vedlo k vysoce uspokojivým výsledkům, které nejen reflektovaly obsah záznamu, na nějž byl prompt nasazen, ale také v menší míře využívaly data použitá při strojovém učení. Obdobně testování překladů existujících popisů bylo přesné a téměř bezchybné. Problémy nastaly při realizaci komplexnějších úloh. Generování klíčových slov na základě celé řady různých kategorií záznamu paralelně v českém a anglickém jazyce se při zavedení kategorií, jež pro zpracování promptu využity být nemají, projevilo jako velmi obtížně proveditelné. Výsledky nebyly při opakovaném testováním vždy konzistentní. U takto složitějšího promptu, kde docházelo k souběhu několika různých pokynů, měla AI tendenci k vyloženým halucinacím a faktickým chybám. Mezi ty můžeme řadit ignorování některých nastavených pravidel, kdy docházelo ke generování klíčových slov na základě zakázaných kategorií a také ke generování osobních a místních jmen v nesprávném tvaru či jazyce. Nadto bylo klíčových slov v poměru k obsahu záznamu poměrně malé množství a ty plně neodpovídaly jeho informačnímu potenciálu, výsledná množina tak nepostihovala všechny relevantní oblasti. Integrací optimalizačních parametrů temperature, frequency a penalty se u komplexních úloh (souhrn a klíčová slova) podařilo výsledky značně zpřesnit, přičemž jako efektivnější se projevila jejich aplikace v případě souhrnu – u klíčových slov nebylo i přes testování promptu při různě nastavených parametrech možné se chybovosti zcela zbavit. Problém omezené obsažnosti generovaného výsledku a místy se vyskytujících nekonzistentních tvarů a překladů osobních i místních jmen nebyl zcela odstraněn. Na druhou stranu se podařilo částečně rozšířit počet generovaných klíčových slov, což zlepšilo praktickou použitelnost výsledků.
Testování OpenAI Chat GPT-4o ukázalo, že AI je schopna dosahovat vysoké přesnosti při jednoduchých a specificky zaměřených úkolech. U složitějších úkolů se objevily určité limity v konzistentnosti a přesnosti, nicméně zavedení pokročilých parametrů AI nástroje vedlo k částečnému zlepšení těchto výsledků.
Výstupy pro koncové uživatele
Pro potřeby demonstrace možného využití ve prospěch koncových uživatelů jsme zpracovali 160 rukopisů české provenience ze sbírek Národní knihovny České republiky. Připravili jsme tři různé úlohy:
- odvozování klíčových slov z TEI P5 XML vstupů v českém a anglickém jazyce (kategorie record)
- vytvoření souhrnu o dokumentu v českém a anglickém jazyce (kategorie record)
- vytvoření indikátorů určujících, jaký typ obsahu může uživatel najít v digitalizovaném dokumentu (kategorie canvases)
Konfigurační balíčky pro testování v AI Debuggeru najdete zde.
Demonstraci obohacení koncového uživatelského rozhraní je možno naživo vidět v testovacím Manuscriptoriu.
Vzniklé informace jsme pak využili k usnadnění vyhledávání v hlavním katalogu (přičemž při budoucím použití se nehodláme omezit jen na katalog).
Usnadnění vyhledávání
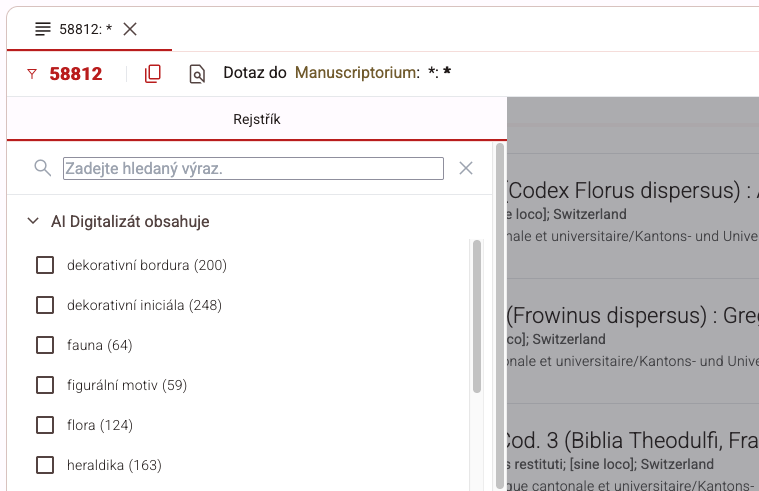
Zavedli jsme novou položku pro vyhledávání pomocí klíčových slov vygenerovaných AI.

Lepší třídění obsahu
Pomocí nově generovaných třídících filtrů se laický uživatel snadno dostane k předmětu svého zájmu.
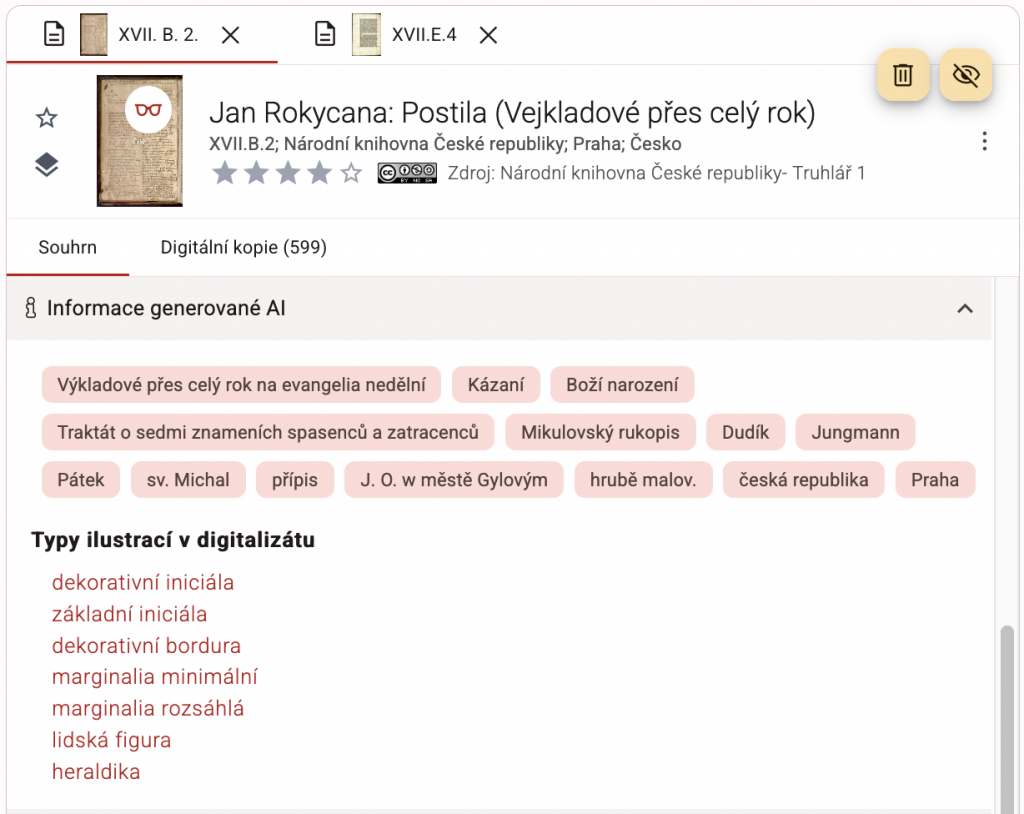
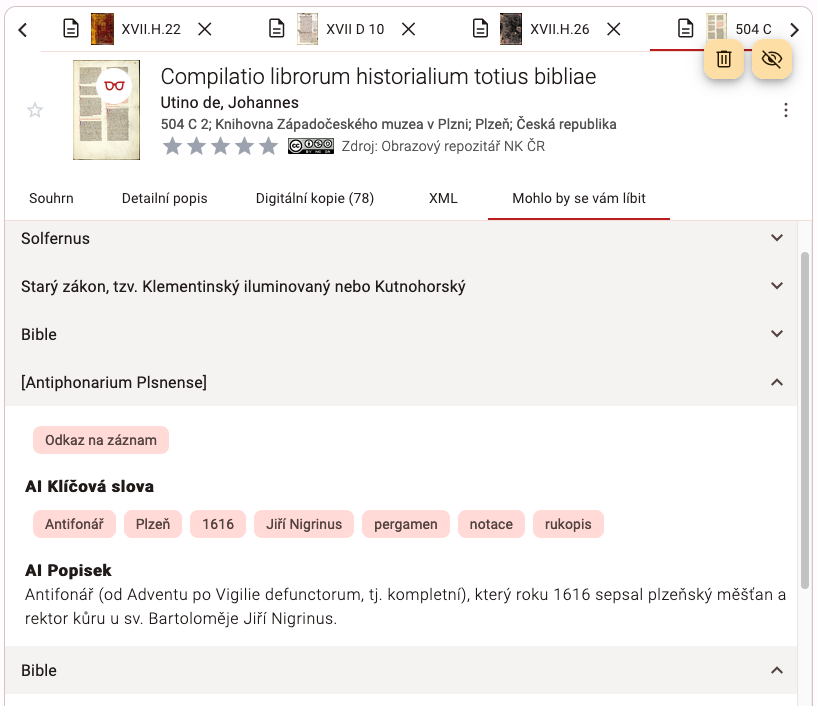
Obohacený souhrn o obsahu dokumentu
Funkce Mohlo by se vám líbit
Pokud uživatel pracuje s vyhledaným dokumentem, pak systém dohledává příbuzné dokumenty pomocí informací nově vytvořených AI a nabízí je uživateli.
AI Debugger – nástroj pro paměťové instituce
Nástroj AI Debugger je komplementárním nástrojem k AI Processoru sloužící k přípravě konfiguračních balíčků obsahovými odborníky. Náročnost obsluhy tohoto nástroje odpovídá jednoduchosti těchto balíčků. Rozhraní je vizuálně rozděleno do 5 hlavních částí: prompt, schéma, vstupní data, náhled a výstup.
Panely AI Debuggeru jsou seřazeny tak, aby pro většinu případů odpovídaly pracovnímu postupu tvorby konfiguračního balíčku.

Prompt
Prompt je čistě textový vstup, který slouží jako slovní zadání pro AI model. Jeho prostřednictvím vysvětlí odborník lidskou formou modelu, jaké úkony se mají na vstupních datech provádět. Tedy například z jaké části záznamu abstrahovat, jaká data pro výstup a případně jak je dodatečně transformovat (např. přeložit z/do jiného jazyka).
Schéma
Schéma je text ve formátu JSON Schema (nástavba formátu zápisu dat JSON), který slouží pro striktní specifikaci struktury výstupních dat z modelu. V rámci schématu se specifikují jednotlivá pole, jejich typ (text, číslo, pravda/nepravda, atd.), pořadí a název.
Díky tomu je výstup pro celou řadu potenciálně různorodých vstupních dat sjednocený, a tedy snadno strojově zpracovatelný.
Vstupní data
Sekce s definicí vstupních dat je o něco komplexnější než ostatní. Základem je výběr typu zdroje dat. Tím může být buď předdefinovaný zdroj pro záznamy (API), nebo IIIF identifikátor pro obrazová data. Jak obrazová data, tak XML záznamy umožňují také vstup z vlastní absolutní URL adresy na konkrétní záznam či obraz dostupný na internetu.
V případě ladění pro Canvas (obrazů) se v této sekci ještě vybírá fáze (1. nebo 2.), pro kterou lazení probíhá.
Pro specifické potřeby je možno nastavit i pokročilé číselné parametry pro AI model, které ovlivňují např. determinismus či slohovou rozmanitost/kreativitu výstupu
Náhled
Před odesláním celého zadání modelu je možné zobrazit náhled vstupních dat do sekce s náhledem, díky které lze ověřit, co přesně model dostane ke zpracování. Při práci se záznamy lze také záznam v této sekci poupravit.
Výstup
Poslední sekce slouží pouze ke čtení a zobrazuje výstup z modelu po zpracování nebo, v případě problému, chybu, která nastala.
Import/Export
V jakékoliv fázi ladění je možné pomocí tlačítka Import/Export otevřít dialog umožňující uložení nebo načtení konfiguračního balíčku, který odpovídá kombinaci hodnot relevantních vstupních polí v nástroji.
Aplikace – odkazy
Ukázkové konfigurační balíčky
- Kategorie Record:
- Kategorie Canvases: